コンパイラの構造
はじめに
久しぶりに Aho氏, Sethi氏, Ullman氏の書いた Compilers(レッド・ドラゴン・ブック)という書籍を目にしたので、昔、コンパイラを作った時の事を思い出しながらコンパイラについてまとめてみました。
Translator (翻訳)
Translatorとは、一つのプログラミング言語(Source Language: 原始言語)で書かれたプログラムを入力として取り、別の言語(Object
Language or Target Language: 目的言語)のプログラムとしてつくり出すプログラムです。
原始言語が FORTRAN, C, Pascal などの高水準言語で、目的言語がアセンブリ言語や機械語といったような低水準言語である時、そのような
Translator をコンパイラ(Compiler) と呼びます。また、原始言語がアセンブリ言語で目的言語が機械語であるものをアセンブラ(Assembler)、ある高水準言語から別の高水準言語に変換するものをプリプロセッサ(Preprocessor) と呼びます。
Phase (構造)
コンパイラは、フェーズと呼ばれる幾つかの行程を経て高級言語を低水準言語に翻訳します。
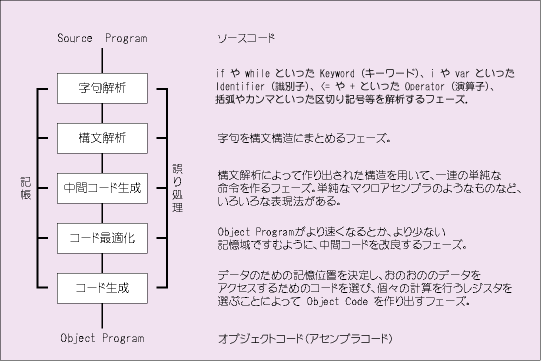
各フェーズを経ている最中に、二つの処理が並行して行われています。一つは、『Table Management (表管理) 又は Book Keeping (記憶)』で、プログラムで用いた名前を覚えておき、型のようなおのおのについての本質的な情報を記録しておきます。この情報を記録するのに用いるデータ構造を Symbol Table と呼びます。もう一つは、『Error Handler (誤り処理)』で、Source Program中に欠陥が検出された時に呼び出されます。プログラマへの警告、及び、フェーズからフェーズに渡される情報の調整を行います。
コンパイラを実現する際には、ひとつ以上のフェーズをまとめてパスと呼び、ひとつのモジュール(プログラム)にします。Source Program又は、ひとつ前のパスの出力を読み込み、その各フェーズで指定されている変換を行い出力を中間ファイルに書き出します。書き出された中間ファイルは、次のパスが読み込みます。
コンパイラを実現する場合、このパスの数によりコンパイラの性能が影響します。複数のパスを持つコンパイラは、ひとつのパスが占有していたメモリ領域を次のパスで再び使用することができるために、メモリ領域が少ししか使用せずに済みます。単一パスのコンパイラは、すべてのフェーズをメモリ領域に割り当てるため、メモリ領域を多く必要とします。しかし、おのおののパスで中間ファイルを読んだり、書いたりすることがないためコンパイル・スピードが速いという利点があります。
字句解析 (Lexical Analyzer)
Source Program とコンパイラとのインターフェース。Source Program を 1文字ずつ組み込み、字句(トークン) と呼ぶ一連の単位に刻んでいきます。おのおののトークンは、単一の論理的なものとして取り扱うことができる文字列を表します。キーワード、識別子、定数、演算子、カンマや括弧などの区切り記号等。構文解析と同一パスに実現されることが多い。
プログラム言語のような複雑なデータを扱うためには、色々な道具が必要になります。バラバラに入ってきた数字や文字を一定の規則にしたがい、変数や予約語となる名前、データとなる数字や文字列、各種の文法上の規則によりプログラムの動作を決定する記号類などに分類してくれる字句解析ルーチンが必要となります。解析された結果は種類とデータが収まったトークンという形で上位の構文解析ルーチンに渡されます。構文解析ルーチンがこのようなトークンを受け取った後、特定の場所から逆の順番で使いたい場合には、トークンの入るスタックが利用されます。
トークン:
プログラムを正規表現によって分割し構文解析の対象としたデータ。通常構造体に、文字列、数、予約語、名前などというカテゴリとデータそのものに分けて収めます。しかし、数字は 1桁目と決めてしまえばキャラクタ型そのものでもよい。構文解析の時点ではカテゴリしか必要がないように分けるのが普通です。
| Identifier(識別子) | [a-zA-Z_]+[0-9a-zA-Z_]* |
| white space | [ \t\n\r] |
| number(数字) | [0-9]+ |
| その他 |
スタック:
スタックはデータを入れたり出したりすることができる入れ物です。ただし、最後に入れたデータが最初に出てくるという特徴を持っています。穴に物を出し入れする動作に似ているので、データを入れる操作をプッシュ、データを取り出す操作をポップと呼びます。スタックに入れるデータは何でもよいが、全て同じ形で扱える必要があります。また、スタックの先頭 (次に取り出せるデータ)や n番目のデータがどうなっているかスタックに影響を与えずに調べられるルーチンが提供されることが多い。
Op stack[256];
Op *sp = stack;
push(a)
Op a;
{
*++sp = a;
}
Op pop()
{
return *sp--;
}
Op top()
{
return *sp;
}
構文解析 (Syntax Analyzer)
A+B といったような式がまとまった文などを解析します。構文構造は、トークンが言語仕様によって許されているパターンと合致するかどうか検査します。トークンを葉とするような Parse Tree (解析木)と呼ばれるツリー構造にはめ込みます。
[Parse Tree (解析木)]
例)A / B * C
* /
/ --- --- --- --- *
-- -- -- -- -- --
A B C A B C
中間コード生成 (Intermediate Code Generation)
解析木をソース・プログラムの中間言語表現に変換します。よく使われる中間言語のひとつとして、Three-Address Code(3番地コード) というものがあります。代表的な 3番地コードの文は『A : B op C』で A, B, Cは被演算子で、opは 2項演算子となります。
[例]上記の解析木を参照すると以下のようになる T1 = A / B T2 = T1 * C (T1及びT2は一時変数の名前)
中間言語としては、算術演算子を用いる文だけでなく、無条件分岐文及び単純な条件付き分岐文が必要となります。これは分岐すべきかどうかを決めるためのひとつの関係を判定するためのものです。大抵のコンパイラは解析木を陽に生成せず、構文解析を行うに連れて直接中間コードを生成してしまいます。
最適化 (Optimization)
このフェーズでは、オブジェクト・プログラムのコードサイズを小さくし、実行スピードを速くするために中間コードの変換を施します。
[例]A は Bや Cの別名でないとする
A := B + C + D -> T := B + C
E := B + C + F A := T + D
E := T + F
左の式を右のような式に置き換えて評価します。しかし、プログラマが上記のようなコーディングをすることはあまり多くありません。もっとも効果のあるのは、コンパイラ自身によって生成される計算から出てくる添字計算などが最適化の対象にあたります。
例えば、機械の主記憶がバイト単位で番地付けされており1語が 4バイトの場合、
A[I] := B[I] + C[I]
という文では 4 * 1を 3回計算する必要があります。これらは最適化によって 4 * 1を 1回しかしないように中間プログラムを修正することができます。このような番地計算は、ソースプログラムのレベルでは表には出てこないので、プログラマが 4 * 1を 1回しかしないように指定することはできません。
後で、最適化の種類についてちょっと説明しますが、最適化の種類によっては、不要なコードを無視したり、ループ処理がソースコードとは異なる処理になったりします。そのため、ソースコードレベルデバッガなどを利用してステップ実行(ソースコード1行ずつ実行)をすると意図せぬ動きをすることがあります。もし、ソースレベルデバッガなどできちんとコードを追っていきたい場合、コンパイル時に最適化のオプションを無効にすると良い。
コード生成 (Code Generation)
中間コードを機械語命令の列に変換します。このフェーズでは、『どの命令を使用するか』『どういう順序で計算を行うべきか』『どのレジスタを使用するか』などの問題を考慮しながらコードを生成していきます。特に冗長なロードとストアを避けるために、レジスタの割り当て方に注意しながらコードを生成することが最善の方法と言えます。
記帳 (Book Keeping)
コンパイラは、ソースプログラムに現れる全てのデータに関する情報を収集する必要があります。例えば、ある変数が整数なのか実数なのか、配列の大きさはいくつなのか、関数の引数はいくつか、といったことを知る必要があります。データに関する情報は、宣言のように陽に与えられるものや、識別子の最初の文字とか識別子が用いられた前後関係のように陰に与えられるものがあります。
誤り処理 (Error Handler)
コンパイラの最も重要な機能のひとつとして、ソースプログラム中の誤りの検出と報告があります。エラーメッセージはプログラマにとって、その誤りがどこで起こったのかが正確にわかるものでなくてはなりません。誤りはコンパイラの全てのフェーズで見つけることができます。
ソースプログラム中の次の字句の綴りが誤っていて、字句解析のフェーズで先に進むことができない。
括弧がないというような構文上の誤りが発生し、構文解析のフェーズでは入力に対する構造を推論するしかない。
中間コードを生成するフェーズでは、被演算子の型が適切でない演算子を検出したりする。
最適化のフェーズにおいても、制御の流れの解析を行い、どこからも決して到達できない文を検出したりする。
コードを生成するフェーズでは、大きすぎて目的の機械語の1語には合わないような定数を見分けることがある。
あるフェーズで誤りを見つけた時には、その誤りを誤り処理系に報告しなければなりません。すると、誤り処理系が適切な診断メッセージを出力します。
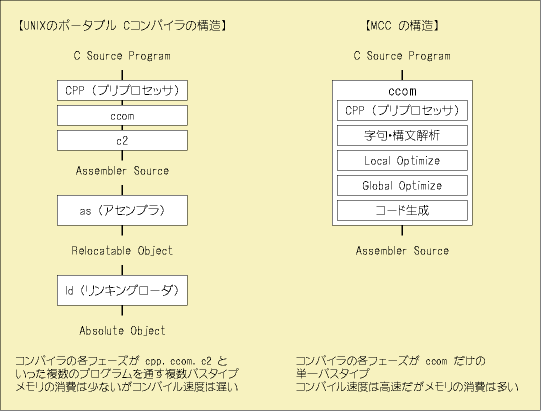
実際に存在するコンパイラの構造
実際に存在するコンパイラで、構造を確認してみましょう。ちょっと古いですが、UNIX に標準で付いていたポータブルCコンパイラと自分で作ったコンパイラ
MCC (Motomiya's C Compiler) の構造の違いを例にとりました。C Compiler は cc コマンドですが、このコマンドは実際には以下のように多くのコマンドを実行しています。
| cpp | #define や #include といったマクロを展開する C プリプロセッサ |
| ccom, c2 | C 言語をアセンブラ言語にコンパイルするコンパイラ(字句、構文解析/最適化) |
| as | アセンブラ言語をリロケータブルオブジェクトに変換するアセンブラ |
| ld | リロケータブルオブジェクトやライブラリーを実行可能なコマンドに変換するリンカ |
実際にコードをコンパイルしているのは ccom, c2 といったプログラムで、cc コマンドはコンパイラ(ccom, c2)やアセンブラ(as),リンカ(ld)を次々と実行するスクリプトのような構造になっています。UNIXで他の言語のコンパイラを実現する場合、Pascal
は pcom、Fortranは fcom という具合に ccom の部分を入れ替えることで別の言語のコンパイラにすることが出来ます(リンクするライブラリーは異なるが、アセンブラやリンカは
C Compiler が実行しているものと同じ)。
いろいろな最適化
■ 一般的な最適化
式の評価 (Constant Folding)
A := 1+2*3-4 ---------> A:=3
不要なジャンプの除去
if A=B goto L1 -------> if A=B goto L3
C := 3 C := 3
D := 6 D := 6
L1: goto L3
goto L3
if A>B goto L5 -------> if A<=B goto L3
goto L3
L5:
到達不能コードの除去 (Dead Code Elimination)
A := 0 -------------> A := 0
goto L1 D := 2
B := 3
C := 1
L1:
D := 2
分岐ルーチンのマージ (Branch Tail Merging)
if i := TRUE ---------> if = TRUE
A := 3 A := 3
B := 8 else
else A := 6
A := 6 endif
B := 8 B := 8
endif
■ ループ・ローテーション (Loop Rotation)
通常ループの終了テストは、ループの先頭で行われ、ループの最後から先頭へ無条件分岐を起こします。そのループではループの反復ごとに、ふたつの分岐命令を実行することになります。もし、コンパイル時に少なくても 1回は必ず実行されることが決定されれば、ループは先頭から入っていくことになります。また、反対に実行が決定されなければループがエントリーする前に終了テストへの無条件分岐が起こります。これらのことから、終了テストをループの最後で行うようにすることが可能となります。このことで、ループの反復 1回につき 1回の分岐ですむことになります。
■ 出入口での最適化 (Entry and Exit Code Optimization)
サブルーチンが非常に小さい場合、出入口の処理 (フレームポインタの生成) はメモリ空間と実行時間の点でそのルーチンの大部分を占めます。しかしフレームポインタは必ず必要な物ではありません。 (デバッグやスタックトレースを行う時などは必要) ひとつ、ふたつのローカル変数を使用する場合なら、フレームポインタを生成しない方がコード部分が小さくなる場合があります。
■ ピープホール最適化 (Peephole Optimize)
この最適化はマシン依存最適化、局所的最適化などとも呼ばれています。あるインストラクションによって構成された一連の処理を同等の処理を行うもっとも短いインストラクションに置き換えます。この最適化は時間を節約しますが、必ずしもメモリ空間を節約するとは限りません。
乗算におけるピープホール最適化(インライン乗算)
[例]MC68020において i=0 0 を掛ける 1 を掛ける CLR.L D2(14サイクル) MILS #0,D1(74サイクル) MULS #1,D1(74サイクル) MOVEQ #0,D2(4サイクル) MOVEQ #0,D1(8サイクル) EXT D1(4サイクル)
■ ストレングス・リダクション (Strength Reduction)
ループを繰り返す毎に一定の大きさで増加していくインデックス変数を含むループと乗算式上において、乗算を加算に置き換えます。ループ上で行われた場合
- ループの最初にアクセスされる配列の要素アドレスをループの外でロードする。
- 配列はレジスタにより間接的にアクセスされる。
- ループを回る毎に要素のサイズがレジスタに加えられ、次のループ中でアクセスされる配列の要素を指すようにする。
ストレングス・リダクションは一定の値を加えることにより、ループ・インデックスを使用した乗算を省略します。
■ ループ・インバリアント解析 (Loop Invariant Analysis)
ループ内の不変な式やアドレス計算をループ内から除去することによりループの速度を向上させるために使用されます。各ループに対して、ループの中で変更されない式やアドレス計算が検出され、これらの計算をループの外に出し値をレジスタの中にストアします。小さいループでは、全ての不変な式は "register mode"でアクセスされ、全ての不変なアドレスは "register indirect mode" でアクセスされます。
■ レジスタの割当て (Register Allocation by Coloring)
使用頻度、変数の大きさ、その他いろいろな要素に基づき、変数をレジスタに割当てていきます。使用されることのない変数の割当ては行いません。使用頻度が高い変数を常にレジスタに入れて使用します。レジスタ割当てを行うアルゴリズムは、各変数のライフタイム(Life Time) を決定するデータ・フロー解析を使用します。このアルゴリズムによって、いくつかの変数のライフタイムが重ならない場合、それらは同一のレジスタに割り当てられます。場合によっては、全てのローカル変数をすべてメモリではなくレジスタに割り当てられることも考えられます。
■ テイル・リカージョン (Tail Recursion)
再帰呼出しのルーチンをループ処理に置き換えます。同様にサブルーチンをコールするようなルーチンを単純な GOTO 文に置き換えます。
簡単なコンパイラの使い方(UNIX編)
コンパイラの構造が理解できると、コンパイラを使う上で非常に役立ちます。
ここでは、GNU C Compiler を例に使い方や一般的なコマンドラインオプションの説明をします。
gcc [コマンドラインオプション] file.c ... [-llib]
コマンドラインオプション |
説明 |
-Idir |
ヘッダーファイルのサーチパスを指定します。 |
-Ldir |
ライブラリーのサーチパスを指定します。 |
-E |
プリプロセッサのみを実行し、その結果を標準出力(画面)に出力します。 |
-S |
アセンブラコードをファイル名に .s を付けたファイルに出力します。 |
-c |
リロケータブルオブジェクトをファイル名に .o を付けたファイルに出力します。 |
-o ExeProg |
実行プログラムに名前を指定します。指定しないと a.out になります。 |
-v |
コンパイラのバージョンや実行ステータスを表示します。 |
-g |
デバッガ用のコードをプログラムに含めます。 |
-p |
プロファイリング用のコードをプログラムに含めます。 |
-O |
コードの最適化(オプチマイズ)を行います。 |
-llib |
ライブラリーを指定します。 |
【コンパイル例】
gcc sample.c |
sample.c がコンパイル/アセンブル/リンクされプログラム a.out が作られる。 | |
gcc -o sample sample.c |
sample.c がコンパイル/アセンブル/リンクされプログラム sample が作られる。 | |
gcc -E sample.c > sample.i |
ample.c の #define, #include などのマクロが展開され sample.i に保存される | |
gcc -S sample.c |
sample.c がコンパイルされ sample.s というアセンブラファイルが作られる。 | |
gcc -c sample.c |
sample.c がコンパイル/アセンブルされ sample.o というリロケータブルオブジェクトファイルが作られる。 |
よく利用する関数(main関数は含まない)を、リロケータブルオブジェクトとしておき、それをまとめてライブラリー化しておくことで再利用が容易になり開発効率が向上します。そのライブラリーを作るには、
関数を記述したソースファイル(file.c)を作成する
コンパイラの
-cコマンドラインオプションで、ソースファイルをコンパイルしリロケータブルオブジェクトファイル(file.o)を作成するarコマンドを使用して、いくつかのリロケータブルオブジェクトファイル(file.o)をライブラリー(libfoo.a)にするranlibコマンドでライブラリーを利用可能にする(System V系 UNIXの場合は不要)
作成したライブラリーの利用は、直接コマンドラインでファイルを指定しても構わないが、通常コンパイラの -l コマンドラインオプションを使用します。このとき、ライブラリー作成で libfoo.a と作成した場合には -lfoo と指定します(lib と .a を取り除いた名前)。つまり、ライブラリーを作成する場合、ファイル名は lib という名前で始まらなければならないという決まりがあります。(# は、コマンドラインプロンプト)
# gcc -c func1.c # gcc -c func2.c # gcc -c func3.c # ar cru libfoo.a func1.o func2.o func3.o # ranlib libfoo.a
ライブラリーを利用するとき、ライブラリーを置いてあるディレクトリーにも注意してください。通常、-l コマンドラインオプションで指定したライブラリーは /usr/lib ディレクトリーにあるものとみなされます。もし別のディレクトリーにある場合、-L コマンドラインオプションを使用してライブラリーのあるディレクトリーを指定します。このディレクトリーの指定はヘッダーファイル(file.h)についても同じことが言えます。通常コンパイラは、#include <xxxx.h> の場合 /usr/include ディレクトリーに、#include "xxxx.h" の場合カレントディレクトリーにヘッダーファイルがあるものと解釈し検索します。もし別のディレクトリーにヘッダーファイルがある場合、-I コマンドラインオプションでヘッダーファイルのあるディレクトリーを指定します。
例をあげて説明しましょう。以下のようにファイルが存在しているとして sample.c をコンパイルするには (# は、コマンドラインプロンプト)
/home/shin/tmp/sample.c /home/shin/tmp/sample.h /home/shin/tmp/lib/libsample.a # pwd /home/shin/tmp # ls -F sample.c sample.h lib/ # # gcc -o sample -I. sample.c -Llib -lsample
となります。-I コマンドラインオプションで指定した "." はカレントディレクトリーを意味します。つまり、最後の行(gcc) では、sample.c をコンパイルするのに、カレントの sample.h を参照し、lib ディレクトリーの下の libsample.a をリンク(正確にはライブラリー内の必要な単体オブジェクト)し、sample というアプリケーションを作成しています。
-I や -L コマンドラインオプションは、複数指定できます。この時、一番左に指定したものが優先度が高くなります。(# は、コマンドラインプロンプト)
# gcc -I/home/shin/include -I/usr/local/include sample.c -L/usr/local/lib -lsample
と指定された場合、ヘッダーファイルは /home/shin/include, /usr/local/include, (/usr/include)
の順番で検索され、ライブラリーは /usr/local/lib, (/usr/lib) の順番で検索されはじめに見つかったものを利用します。(gcc
の場合、もう少し別のディレクトリーも検索されます。)
このほかに、ライブラリーを利用する上で注意しなければならないのは、ライブラリーを指定する順番です。コンパイラ(実際にはリンカである ld)は、コマンドラインで指定した順番にライブラリー内のリロケータブルオブジェクトを参照し未解決な関数を解決していきます。
例えば、ライブラリ libbar1.a, libbar2.a 双方に関数 foo() の定義を含むリロケータブルオブジェクトファイル(file.o)が含まれており、sample.c で関数 foo() を利用している場合:
gcc sample.c -lbar2 -lbar1
とすると libbar1.a ではなく libbar2.a に含まれるリロケータブルオブジェクトファイル(file.o)をリンクします。また、UNIX
のリンカは、ライブラリーに含まれる関数単体をプログラムにリンクするのではなく、解決しようとする関数の含まれるリロケータブルオブジェクトファイル(file.o)をリンクします。このため、リロケータブルオブジェクトファイルやライブラリーの作り方によっては(特にリロケータブルオブジェクトファイル[xxxx.o]の中に複数の関数が定義してある場合など)、リンク時に関数の多重定義となる恐れがあるので注意してください。一番初めに指定したファイル(一番左のファイル)から未解決な関数を解決していくので、コンパイルするときは以下のような順番で指定したほうが良いと覚えておいてください。
gcc -o sample -I/path/path main.c sub1.c sub2.o -L/path/path -lbar2 -lbar1
リンクの順番は、main() 関数を含むファイルをはじめに指定し、コンパイルの必要なソースファイル、リロケータブルオブジェクトファイル、ライブラリーといった順番でモジュールを指定することで、意図した関数を使用してプログラムを作成することが出来ます。
また、ライブラリーに含まれる関数が別の関数をコール(参照)しており、その関数が別のライブラリーに定義されているような場合、ライブラリーを指定する順番によってはリンク時に未定義エラーになるので、ライブラリーを指定する順番(左から評価される)には十分に注意して下さい。C
コンパイラでは、ライブラリーを指定しなくても複数指定しても必ず一番最後に標準Cライブラリ (-lc または libc.a)がリンクされます。
【リンカ(リンキングローダー)の動きからライブラリーを作る際の注意点を考える】
《準備》
単純なサンプルコードで動きを調べてみます。関数を呼び出すメインプログラム main.c を以下のように用意します。
#include <stdio.h>
main()
{
foo();
bar();
}
続いて、bar()関数が定義されたサブプログラム bar1.o を持つライブラリ libbar1.a を用意します。
bar()
{
printf("bar1::bar\n");
}
さらに、foo()関数とbar()関数が定義されたサブプログラム bar2.o を持つライブラリ libbar2.a を用意します。
foo()
{
printf("bar2::foo\n");
}
bar()
{
printf("bar2::bar\n");
}
ライブラリーにしておきましょう。(# は、コマンドラインプロンプト/System V 系 UNIX の場合 ranlib は不要)
# gcc -c bar1.c # ar cru libbar1.a bar1.o # ranlib libbar1.a # gcc -c bar2.c # ar cru libbar2.a bar2.o # ranlib libbar2.a
《リンクテスト1》
# gcc main.c -L. -lbar1 -lbar2 ld: fatal: symbol `bar' is multiply-defined....
この場合、 main.c では定義されていない bar()関数を ライブラリ libbar1.a の bar1.o から取得し、足りない foo()関数をライブラリ libbar2.a の bar2.o から取得しようとします。しかし、bar2.o は bar()関数も持っているため bar()関数が多重定義エラーとなりコンパイルが失敗します。
そこで
# gcc main.c -L. -lbar2 -lbar1 # ./a.out bar2::foo bar2::bar #
とした場合、 main.c では定義されていない foo(),bar()関数を ライブラリ libbar2.a の bar2.o から取得しコンパイルが完了します。ライブラリ libbar1.a は使用されません。
双方のライブラリの bar()関数が同じ動作をするのであればどちらか一方を利用すれば問題はありませんが、機能が異なるためライブラリlibbar1.a の bar()関数、ライブラリ libbar2.a の foo()関数を利用したいとなった場合、このままではどうしようもありません。
ライブラリ libbar2.a の単体オブジェクト bar2.o 作りを以下のように関数ごとの単体オブジェクトになるように変更する必要があります。
先ほどのサブプログラム bar2.c の関数を分割して、foo()関数が定義されたサブプログラム foo2.o と bar()関数が定義されたサブプログラム bar2.o を持つライブラリ libbar2.a に変更します。(# は、コマンドラインプロンプト/System V 系 UNIX の場合 ranlib は不要)
# gcc -c foo2.c # gcc -c bar2.c # ar cru libbar2.a foo2.o bar2.o # ranlib libbar2.a
一番初めのようにコンパイルすると
# gcc main.c -L. -lbar1 -lbar2 # ./a.out bar2::foo bar1::bar #
main.c では定義されていない bar()関数を ライブラリ libbar1.a の bar1.o から取得し foo()関数を ライブラリ libbar2.a の foo2.o から取得しコンパイルが完了します。これで意図したとおりの関数が利用されたことになります。
今度は、以下のような main プログラムの場合を考えて見ましょう。
#include <stdio.h>
main()
{
bar();
foo();
bar();
}
このとき、はじめの bar()関数がライブラリ libbar1.a の bar1.o から次の bar()関数が、ライブラリ libbar2.a の bar2.o を利用したい場合、ライブラリの順番をどう変えようがはじめに指定されたライブラリの bar() 関数をリンクしてしまいます。
# gcc main.c -L. -lbar1 -lbar2 # ./a.out bar1::bar bar2::foo bar1::bar # gcc main.c -L. -lbar2 -lbar1 # ./a.out bar2::bar bar2::foo bar2::bar #
これを回決する手段は、関数名をユニークなものにするしかありません。
これらのことを踏まえると、ライブラリーを作成する場合:
リロケータブルオブジェクトファイル(
xxxx.o)ひとつに対して、ひとつの関数定義(他で絶対に定義されることがないもの同士であれば複数定義でも問題はない)いろいろなライブラリーを利用することを考慮した関数のネーミング
といったことが基本的な注意点であることがわかります。
nm コマンドを利用することで、ライブラリーやリロケータブルオブジェクトファイルに「どんな関数が定義されているか」「どんな関数をコール(参照)しているか」調べることが出来ます。詳しくは man コマンドで調べて下さい。
ライブラリーで拡張子 .a のついたものを例に説明しましたが、UNIX では、実行モジュール(プログラム)にスタティックリンクされるスタティックライブラリー(.a)と実行時にダイナミックにリンクされるシェアードライブラリー(.so)があります。
余談:今までのところで、ソースファイルやライブラリーを指定してコンパイルすることでプログラムを作成できることがわかったかと思いますが、実際には見えないところで多く作業やオブジェクトファイル/ライブラリーをリンクしています。コマンドラインの -v オプションを指定することで、実際にどのようなステップでどのようなものがリンクされていくのかがわかります。
例では、単純に a.c をコンパイルした時にどのようなことが行われているか見てみましょう。余分な部分は削除しています。この色が起動されているコマンド。/var/tmp/xxxxxx は、a.c が各コマンドで変換/コンパイルされたものを一時的に保存しておくためのファイル。(# は、シェルプロンプト)
# gcc -v a.c
...
/usr/local/gnu/lib/gcc-lib/sparc-solaris2/2.7.2/cpp -lang-c -v -undef -D__GNUC__=2 -D__GNUC_MINOR__=7 -Dsun -Dsparc -Dunix -D__svr4__ -D__SVR4 -D__GCC_NEW_VARARGS__ -D__sun__ -D__sparc__ -D__unix__ -D__svr4__ -D__SVR4 -D__GCC_NEW_VARARGS__
-D__sun -D__sparc -D__unix -Asystem(unix) -Asystem(svr4) -Acpu(sparc) -Amachine
(sparc) a.c /var/tmp/cca006Oo.i
...
/usr/local/gnu/lib/gcc-lib/sparc-solaris2/2.7.2/cc1 /var/tmp/cca006Oo.i -quiet
-dumpbase a.c -version -o /var/tmp/cca006Oo.s
...
/usr/ccs/bin/as -V -Qy -s -o /var/tmp/cca006Oo1.o /var/tmp/cca006Oo.s
...
/usr/ccs/bin/ld -V -Y P,/usr/ccs/lib:/usr/lib -Qy /usr/local/gnu/lib/gcc-lib/sparc-solaris2/2.7.2/crt1.o /usr/local/gnu/lib/gcc-lib/sparc-solaris2/2.7.2/crti.o /usr/ccs/lib/values-Xa.o /usr/local/gnu/lib/gcc-lib/sparc-solaris2/2.7.2/crtbegin.o -L/usr/local/gnu/lib/gcc-lib/sparc-solaris2/2.7.2 -L/usr/ccs/bin -L/usr/ccs/lib -L/usr/local/gnu/lib /var/tmp/cca006Oo1.o -lgcc -lc -lgcc /usr/local/gnu/lib/gcc-lib/sparc-solaris2/2.7.2/crtend.o /usr/local/gnu/lib/gcc-lib/sparc-solaris2/2.7.2/crtn.o
...
#
-v コマンドラインオプションを使用することで、Cソースファイル a.c がいろいろなコマンドによって変換/コンパイルされ最終的にいろいろなモジュールがリンクされていることが確認できます。
cppが、Cプログラム中のマクロ(#define, #include)を展開してxxxxx.i(マクロを展開した C ソースプログラム)というファイルに一時的に保存(最終的に消去される)しています。cc1が、cppによってマクロを展開されたファイルをコンパイルしてxxxxx.s(アセンプラソース)というファイルに一時的に保存しています。asが、アセンブラソースをアセンブルしてxxxxx.o(リロケータブルオブジェクト)というファイルに一時的に保存しています。ldが、必要なモジュールやリロケータブルオブジェクト、ライブラリーをリンクして実行可能なプログラムを作成しています。ここで、
crt1.oというオブジェクトファイルが見つかりますが、これは UNIX でアプリケションを作る場合必ず必要になる初期化モジュール(I/Oなどのハードウェアデバイス依存の差異をこのモジュールが吸収している)です。このモジュールがmain関数をコールしています。-lgcc(libgcc.a) というライブラリが見つかりますが、これはgccを利用する場合必要になるライブラリーで無条件にリンクされるライブラリーです。-lc(libc.a) というライブラリーが見つかりますが、これは標準 Cライブラリーでprintf, getc, mallocなどの標準的な関数が含まれており無条件にリンクされます。gccでは、ライブラリーを指定しなくても幾つかライブラリーを指定しても、必ず最後に-lc -lgccという二つのライブラリーがリンクされます





